
Many applications only need the insert, search and delete operations of a dynamic set. Example: symbol table in a compiler.
Hash tables are an effective approach. Under reasonable assumptions, they have O(1) operations, but they can be Θ(n) worst case
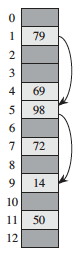
Hash tables generalize arrays. Let's look at the idea with arrays first. Given a key k from a universe U of possible keys, a direct address table stores and retrieves the element in position k of the array.
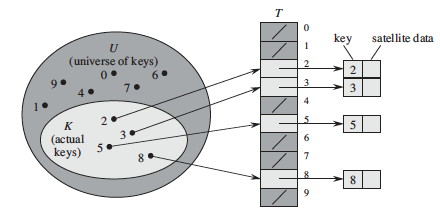
Direct addressing is applicable when we can allocate an array with one element for every key (i.e., of size |U|). It is trivial to implement:

However, often the space of possible keys is much larger than the number of actual keys we expect, so it would be wasteful of space (and sometimes not possible) to allocate an array of size |U|.
Hash tables are also arrays, but typically of size proportional to the number of keys expected to be stored (rather than to the number of keys).
If the expected keys K ⊂ U, the Universe of keys, and |K| is substantially smaller than |U|, then hash tables can reduce storage requirements to Θ(|K|).
A hash function h(k) maps the larger universe U of external keys to indices into the array. Given a table of size m with zero-based indexing (we shall see why this is useful):
The major issue to deal with in designing and implementing hash tables is what to do when the hash function maps multiple keys to the same table entry.
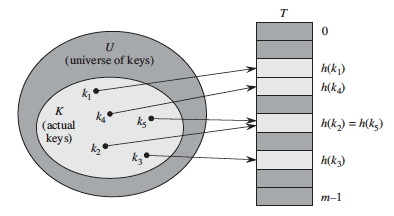
Collisions may or may not happen when |K| ≤ m, but definitely happens when |K| > m. (Is there any way to avoid this?)
There are two major approaches: Chaining (the preferred method) and Open Addressing. We'll look at these and also hash function design.
A simple resolution: Put elements that hash to the same slot into a linked list. This is called chaining because we chain elements off the slot of the hash table.
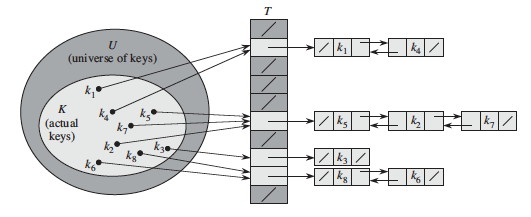
Implementation is simple if you already have implemented linked lists:

What are the running times for these algorithms? Which can we state directly, and what do we need to know to determine the others?
How long does it take to find an element with a given key, or to determine that there is no such element?
Let's analyze averge-case performance under the assumption of simple uniform hashing: any given element is equally likely to hash into any of the m slots:
Consider two cases: Unsuccessful and Successful search. The former analysis is simpler because you always search to the end, but for successful search it depends on where in T[h(k)] the element with key k will be found.
Simple uniform hashing means that any key not in the table is equally likely to hash to any of the m slots.
We need to search to end of the list T[h(k)]. It has expected length E[nh(k)] = α = n/m.
Adding the time to compute the hash function gives Θ(1 + α). (We leave in the "1" term for the initial computation of h since α can be 0, and we don't want to say that the computation takes Θ(0) time).
We assume that the element x being searched for is equally likely to be any of the n elements stored in the table.
The number of elements examined during a successful search for x is 1 more than the number of elements that appear before x in x's list (because we have to search them, and then examine x).
These are the elements inserted after x was inserted (because we insert at the head of the list).
Need to find on average, over the n elements x in the table, how many elements were inserted into x's list after x was inserted. Lucky we just studied indicator random variables!
For i = 1, 2, ..., n, let xi be the ith element inserted into the table, and let ki = key[xi].
For all i and j, define the indicator random variable:
Xij = I{h(ki) = h(kj)}. (The event that keys ki and kj hash to the same slot.)

Simple uniform hashing implies that Pr{h(ki) = h(kj)} = 1/m (Why?)
Therefore, E[Xij] = 1/m by Lemma 1 (Topic #5).
The expected number of elements examined in a successful search is those elements j that are inserted after the element i of interest and that end up in the same linked list (Xij):
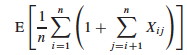
I fill in some of the implicit steps in the rest of the CLRS text analysis. First, by linearity of expectation we can move the E in:
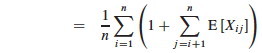
That is the crucial move: instead of analyzing the probability of complex events, use indicator random variables to break them down into simple events that we know the probabilities for. In this case we know E[Xi,j] (if you don't know, ask the lemming above):
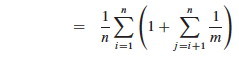
Multiplying 1/n by the terms inside the summation,
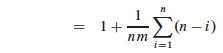
Splitting the two terms being summed, the first is clearly n2, and the second is the familiar sum of the first n numbers:
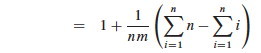
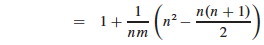
Distributing the 1/nm, we get 1 + (n2/nm - n(n+1)/2nm = 1 + n/m - (n+1)/2m = 1 + 2n/2m - (n+1)/2m, and now we can combine the two fractions:
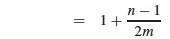
Now we can turn two instances of n/m into α with this preparation: 1 + (n - 1)/2m = 1 + n/2m - 1/2m = 1 + α/2 - n/2mn =
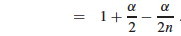
Adding the time (1) for computing the hash function, the expected total time for a successful search is:
Θ(2 + α/2 - α/2n) = Θ(1 + α).
since the third term vanishes in significance as n grows, and the constants 2 and 1/2 have Θ(1) growth rate.
Thus, search is an average of Θ(1 + α) in either case.
If the number of elements stored n is bounded within a constant factor of the number of slots m, i.e., n = O(m), then α is a constant, and search is O(1) on average.
Since insertion takes O(1) worst case and deletion takes O(1) worst case when doubly linked lists are used, all three operations for hash tables are O(1) on average.
We went through that analysis in detail to show again the utility of indicator random variables and to demonstrate what is possibly the most crucial fact of this chapter, but we won't do the other analyses in detail. With perserverence you can similarly unpack the other analyses.
Ideally a hash function satisfies the assumptions of simple uniform hashing.
This is not possible in practice, since we don't know in advance the probability distribution of the keys, and they may not be drawn independently.
Instead, we use heuristics based on what we know about the domain of the keys to create a hash function that performs well.
Hash functions assume that the keys are natural numbers. When they are not, a conversion is needed. Some options:
A common hash function: h(k) = k mod m.
(Why does this potentially produce all legal values, and only legal
values?)
Advantage: Fast, since just one division operation required.
Disadvantage: Need to avoid certain values of m, for example:
A prime number not too close to an exact power of 2 is a good choice for m.
h(k) = Floor(m(k A mod 1)), where k A mod 1 = fractional part of kA.
Disadvantage: Slower than division.
Advantage: The value of m is not critical.
The book discusses an implementation that we won't get into ...
Our malicious adversary is back! He's choosing keys that all hash to the same slot, giving worst case behavior and gumming up our servers! What to do?
Random algorithms to the rescue: randomly choose a different hash function each time you construct and use a new hash table.
But each hash function we choose has to be a good one. Can we define a family of good candidates?
Consider a finite collection Η of hash functions that map universe U of keys into {0, 1, ..., m-1}.
Η is universal if for each pair of keys k, l ∈ U, where k ≠ l, the number of hash functions h ∈ Η for which h(k) = h(l) is less than or equal to |Η|/m (that's the size of Η divided by m).
In other words, with a hash function h chosen randomly from Η, the probability of collision between two different keys is no more than 1/m, the chance of a collision when choosing two slots randomly and independently.
Universal hash functions are good because (proven as Theorem 11.3 in text):
Therefore, the expected time for search is O(1).
One candidate for a collection Η of hash functions is:
Η = {hab(k) : hab(k) = ((ak + b) mod p) mod m)}, where a ∈ {1, 2, ..., p-1} and b ∈ {0, 1, ..., p-1}, where p is prime and larger than the largest key.
See CLRS for the details, including proof that this provides a universal set of hash functions. Java built in hash functions take care of much of this for you: read the Java documentation for details.
Open Addressing seeks to avoid the extra storage of linked lists by putting all the keys in the hash table itself.
Of course, we need a way to deal with collisions. If a slot is already occupied we will apply a systematic strategy for searching for alternative slots. This same strategy is used in both insertion and search.
Examining a slot is called a probe. We need to extend the hash function h to take the probe number as a second argument, so that h can try something different on subsequent probes. We count probes from 0 to m-1 (you'll see why starting at probe 0 is useful later when we define double hashing), so the second argument takes on the same values as the result of the function:
h : U x {0, 1, ... m-1} → {0, 1, ... m-1}
We require that the probe sequence
⟨ h(k, 0), h(k, 1) ... h(k, m-1) ⟩
be a permutation of ⟨ 0, 1, ... m-1 ⟩. Another way to state this requirement is that if we have as many probes as positions all the positions are visited exactly once.
There are three possible outcomes to a probe: k is in the slot probed (successful search); the slot contains NIL (unsuccessful search); or some other key is in the slot (need to continue search).
The strategy for this continuation is the crux of the problem, but first let's look at the general pseudocode.
The pseudocode below does not make a committment as to how subsquent probes are handled: that is up to the function h(k, i). The pseudocode just handles the mechanics of trying until success or an error condition is met.
Insertion returns the index of the slot it put the element in k, or throws an error if the table is full:

Search returns either the index of the slot containing element of key k, or NIL if the search is unsuccessful:

Deletion is a bit complicated. We can't just write NIL into the slot we want to delete. (Why?)
Instead, we write a special value DELETED. During search, we treat it as if it were a non-matching key, but insertion treats it as empty and reuses the slot.
Problem: With this approach to deletion, the search time is no longer dependent on α. (Why?)
The ideal is to have uniform hashing, where each key is equally likely to have any of the m! permutations of ⟨0, 1, ... m-1⟩ as its probe sequence. But this is hard to implement: we try to guarantee that the probe sequence is some permutation of ⟨0, 1, ... m-1⟩.
We will define the hash functions in terms of auxiliary hash functions that do the initial mapping, and define the primary function in terms of its ith iterations, where 0 ≤ i < m.
Given an auxiliary hash function h', the probe sequence starts at h'(k), and continues sequentially through the table:
h(k, i) = (h'(k) + i) mod m
Problem: primary clustering: sequences of keys with the same h' value build up long runs of occupied sequences.
Quadratic probing is attempt to fix this ... instead of reprobing linearly, QP "jumps" around the table according to a quadratic function of the probe, for example:
h(k, i) = (h'(k) + c1i + c2i2) mod m,
where c1 and c2 are constants.
Problem: secondary clustering: although primary clusters across sequential runs of table positions don't occur, two keys with the same h' may still have the same probe sequence, creating clusters that are broken across the same sequence of "jumps".
A better approach: use two auxiliary hash functions h1 and
h2, where h1 gives the initial probe and
h2 gives the remaining probes (here you can see that having
i=0 initially drops out the second hash until it is needed):
h(k, i) = (h1(k) + ih2(k)) mod m.
h2(k) must be relatively prime to m (relatively prime means they have no factors in common other than 1) to guarantee that the probe sequence is a full permutation of ⟨0, 1, ... m-1⟩. Two approaches:
There are Θ(m2) different probe sequences, since each possible combination of h1(k) and h2(k) gives a different probe sequence. This is an improvement over linear or quadratic hashing.
The textbook develops two theorems you will use to compute the expected number of probes for unsuccessful and successful search. (These theorems require α < 1 because an expression 1/1−α is derived and we don't want to divide by 0 ... and of course at α = 1 the table is full!)
Theorem 11.6: Given an open-address hash table with load factor α = n/m < 1, the expected number of probes in an unsuccessful search is at most 1/(1 − α), assuming uniform hashing.
Theorem 11.8: Given an open-address hash table with load factor α = n/m < 1, the expected number of probes in a successful search is at most (1/α) ln (1/(1 − α)), assuming uniform hashing and assuming that each key in the table is equally likely to be searched for.
We leave the proofs for the textbook, but note particularly the "intuitive interpretation" in the proof of 11.6 of the expected number of probes on page 275:
E[X] = 1/(1-α) = 1 + α + α2 + α3 + ...
We always make the first probe (1). With probability α < 1, the first probe finds an occupied slot, so we need to probe a second time (α). With probability α2, the first two slots are occupied, so we need to make a third probe ...