The problem is an extension of Single-Source Shortest Paths to all sources. We start by repeating the definition.
Input is a directed graph G = (V, E) and a weight function w: E → ℜ. Define the path weight w(p) for p = ⟨v0, v1, ... vk⟩ to be the sum of edge weights on the path:
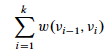
The shortest path weight from u to v is:
A shortest path from u to v is any path such that w(p) = δ(u, v).
Then the all-pairs shortest paths problem is to find a shortest path and the shortest path weight for every pair u, v ∈ V.
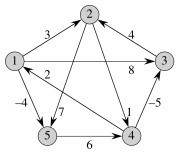
(Consider what this means in terms of the graph shown above right. How many shortest path weights would there be? How many paths?)
An obvious real world application is computing mileage charts.
Unweighted shortest paths are also used in social network analysis to compute the betweeness centrality of actors. (Weights are usually tie strength rather than cost in SNA.) The more shortest paths between other actors that an actor appears on, the higher the betweeness centrality. This is usually normalized by number of paths possible. This measure is one estimate of an actor's potential control of or influence over ties or communication between other actors. (If this sounds interesting, consider taking ICS 422 Network Science Methodology Spring 2021.)
Since we already know how to compute shortest paths from s to every v ∈ V (the Single Source version from the last lecture), why not just iterate one of these algorithms for each vertex v ∈ V as the source?
That will work, but let's look at the complexity and constraints.
Bellman-Ford is O(V E), and it would have to be run |V| times, so the cost would be O(V2E) for any graph.

On sparser graphs, Dijkstra's algorithm has better asymptotic performance. Dijkstra's is O(E lg V) with the binary min-heap (faster with Fibonacci heaps).
What a pity. But why can't we just get rid of those pesky negative weights?
Proposal: How about adding a constant value to every edge?
Since we have added the same constant value to everything, we are just scaling up the costs linearly and should obtain the same solutions, right?
For example, in this graph the shortest path from s to w is s--x--y--z--w, but as you found in the previous lecture Dijkstra's algorithm can't find it because there is a negative weight. (Why? What went wrong? Go back and trace the algorithm if you don't remember.):
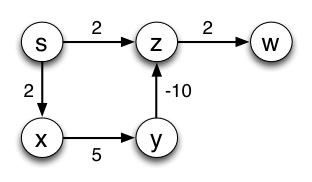
So, let's add 10 to every edge:
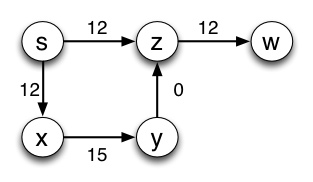
and the shortest path is .... Oops! s--z--w!
The strategy suggested above does not work because it does not add a constant amount to each path; rather it adds a constant to each edge and hence longer paths are penalized disproportionately.
Perhaps because of this, the first algorithm for all-pairs shortest paths (in the 1960's) by Floyd based on Warshall's work took a dynamic programming approach. (We'll get to that later.) But then Johnson had a bright idea in 1977 that salvaged the greedy approach.
We might ask: Would you already need to know the paths to adjust them proportionally?
Donald Johnson figured out how to make a graph that has all edge weights ≥ 0, and is also equivalent for purposes of finding shortest paths without knowing the paths in advance..
We have been using a weight function w : V⊗V → ℜ that gives the weight for each edge (i, j) ∈ E, or has value ∞ otherwise. (When working with adjacency list representations, it may be more convenient to write w : E → ℜ and ignore (i, j) ∉ E.)
We want to find a modified weight function ŵ that has these properties:
If property 1 is met, it suffices to find shortest paths with ŵ. If property 2 is met, we can do so by running Dijkstra's algorithm from each vertex. But how do we come up with ŵ?
Johnson figured out that if you add a weight associated with the source vertex and subtract a weight associated with the target vertex, you preserve shortest paths. Surprisingly, it does not matter what these weights are.

Given a directed, weighted graph G = (V, E), w : E → ℜ, let h be any function (bad-ass lemming don't care!) such that h : V → ℜ.
For all (u, v) ∈ E define
ŵ(u, v) = w(u, v) + h(u) − h(v).
Let p = ⟨v0, v1, ..., vk⟩ be any path from v0 to vk.
Then p is a shortest path from v0 to vk under w iff p is a shortest path from v0 to vk under ŵ.
Furthermore, G has a negative-weight cycle under w iff G has a negative-weight cycle under ŵ.
Proof: First we'll show that ŵ(p) = w(p) + h(v0) − h(vk); that is, that the defined relationship transfers to paths. Starting with the definition of the weight of a path as the sum of the weights of the edges (first line) and then substituting the above definition (second line):
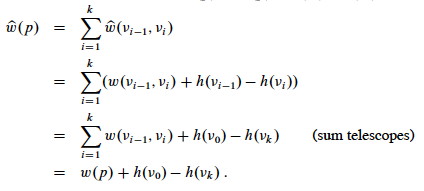
(Notice that when we collapse the telescoping sum we remove h(v0) − h(vk) from the scope of the summation.)
Therefore, any path from v0 to vk has ŵ(p) = w(p) + h(v0) − h(vk).
Since h(v0) and h(vk) don't depend on the path from v0 to vk, if one path from v0 to vk is shorter than another with w, it will also be shorter with ŵ.
Now we need to show that ∃ negative-weight cycle with w iff ∃ negative-weight cycle with ŵ.
Let cycle c = ⟨v0, v1, ..., vk⟩ where v0 = vk. Then:
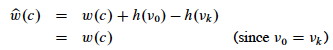
Therefore, c has a negative-weight cycle with w iff it has a negative-weight cycle with ŵ.
Implications: It's remarkable that under this definition of ŵ, h can assign any weight to the vertices and shortest paths and negative weight cycles will be preserved. This gets us Property 1. How can we choose h to get Property 2?
Property 2 states that ∀ (u, v) ∈ E, ŵ(u, v) ≥ 0, or in English, all weights are nonnegative.
Since we have defined ŵ(u, v) = w(u, v) + h(u) − h(v), to get property 2 we need an h : V → ℜ for which we can show that w(u, v) + h(u) − h(v) ≥ 0.
The motivation for how this is done derives from a section on difference constraints in Chapter 24 that we did not cover, so we'll just have to take this as an insight out of the blue ....
Define G' = (V', E')
That is, we construct G' by adding a vertex s to the graph and installing a 0-weight edge from it to all other vertices.
Since no edges enter s, G' has the same cycles as G, including negative weight cycles if they exist.
Since s has a path to all vertices, the following definition is well formed (applies to all v ∈ G).
Define h(v) = δ(s, v) for all v ∈ V.
Important: We put a 0-weighted link from s to every other vertex v, so isn't δ(s, v) always 0? When is it not 0? What does it tell us if it is not 0? Look for an example in the graph shown!
Claim: ŵ(u, v) = w(u, v) + h(u) − h(v) ≥ 0.
Proof: By the triangle inequality,
δ(s, v) ≤ δ(s, u) + w(u, v),
Substituting h(v) = δ(s, v) (as defined above) and similarly for u,
h(v) ≤ h(u) + w(u, v).
Subtracting h(v) from both sides,
w(u, v) + h(u) − h(v) ≥ 0.

The algorithm constructs the augmented graph G' (line 1), uses Bellman-Ford from s to check whether there are negative weight cycles (lines 2-3), and if there are none this provides the δ(s, v) values needed to compute h(v) (lines 4-5).
Then it does the weight adjustment with h (lines 6-7), and runs Dijkstra's algorithm from each start vertex (lines 9-10), reversing the weight adjustment to obtain the final distances put in a results matrix D (lines 11-12).
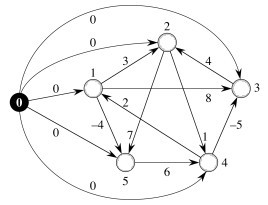
Let's start with this graph:
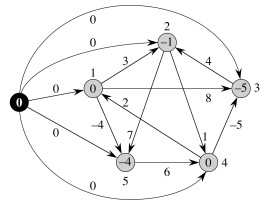
First we construct G' by adding s (the black node) and edges of weight from s 0 to all other vertices. The original weights are still used. This new graph G' is shown to the right. Vertex numbers have been moved outside of the nodes.
Then we run Bellman-Ford on this graph with s (the black node) as the start vertex. The resulting path distances δ(s, v) are shown inside the nodes to the right. Remember that h(v) = δ(s, v), so that these are also the values we use in adjusting edge weights (next step).
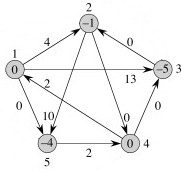
In the next graph to the left, the edge weights have been adjusted to
ŵ(u, v) = w(u, v) +
h(u) − h(v). For example, the edges ...
(1, 2), previously weighted 3, has been updated to 3 + 0
− (-1) = 4
(1, 5), previously weighted -4, has been updated to -4 +
0 − (-4) = 0.
(3, 2), previously weighted 4, has been updated to 4 + (-5) − (-1) = 0.
All weights are non-negative, so we can now run Dijkstra's algorithm from each vertex u as source (shown in black in the next step) using ŵ.
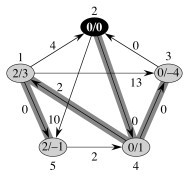
To the right is an example of one pass, starting with vertex 2.
Within each vertex v the values δ̂(2, v) and δ(2, v) = δ̂(2, v) + h(2) − h(u) are separated by a slash.
The values for δ̂(2, v) were computed by running Dijkstra's algorithm with start vertex 2, using the modified weights ŵ. But to get the correct path lengths in the original graph we have to map this back to w.
Of course, node 2 is labeled "0/0" for δ̂(2, 2) and δ(2, 2), respectively, because it costs 0 to get from a vertex to itself in any graph that does not have negative weight cycles.
The cost to get to vertex 4 is 0 in the modified graph. To get the cost in the original graph, we reverse the adjustment that was done in computing w': we now subtract the source vertex weight h(2) = −1 (from figure above) and add the target vertex weight h(4) = 0, so 0 − (−1) + 0 = 1. That is where the "1" on node 4 came from.
But that example was for a path of length 1: let's look at a longer one. Node 5 has "2/-1". Dijkstra's algorithm found the lowest cost path ⟨(2, 4), (4, 1), (1, 5)⟩ to vertex 5, at a cost of 2 using the edge weights w'. To convert this into the path cost under edge weights w, we do not have to subtract the source vertex weight h(u) and add the target vertex weight h(v) for every edge on the path, because it is a telescoping sum. We only have to subtract the source vertex weight h(2) = −1 for the start of the path and add the target vertex weight h(5) = −4 for the end of the path.
Thus δ(5) = δ̂(5) − h(2) + h(5) = 2 − (−1) + (−4) = −1.
Similarly, the numbers after the "/" on each node are δ(v) in the original graph: these are the "answers" for the start vertex used in the given Dijkstra's run. We collect all these answers in matrix D across all vertices.
1. Θ(V) to compute G';
2-3. O(V E) to run Bellman-Ford;
4-5. O(V) to run compute h(v);
6-7. Θ(E) to compute ŵ; and
8. Θ(V2) to initialize D; but
9-12. these are all dominated by O(V E lg V) to run Dijkstra |V| times with a binary min-heap implementation.
Not surprisingly, this time complexity is the same as iterated Dijkstra's, but it will handle negative weights.
Asymptotic performance can be improved to O(V2 lg V + V E) using Fibonacci heaps.
We should also be aware of dynamic programming approaches to solving all-pairs shortest paths. We already saw in Topic 18 that any subpath of a shortest path is a shortest path; thus there is optimal substructure. There are also overlapping subproblems since we can extend the solution to shorter paths into longer ones. Two approaches differ in how they chararacterize the recursive substructure.
CLRS first develop a dynamic programming solution that is similar to matrix multiplication. We discuss this solution informally here, but will favor the Floyd-Warshall algorithm in the next section.
Matrices are a natural representation for all-pairs shortest paths as we need O(V2) memory elements just to represent the final results, so it isn't terribly wasteful to use a non-sparse graph representation (although for very large graphs one can use a sparse matrix representation).
A shortest path p between distinct vertices i and j can be decomposed into a shortest path from i to some vertex k, plus the final edge from k to j. In case that i is directly connected to j, then k=j and we define the length of a shortest path from a vertex to itself to be 0.
This dynamic programming approach builds up shortest paths that contain at most m edges. For m = 0, all the shortest paths from vertices to themselves are of length 0; and others are infinite. For m = 1, the adjacency matrix gives the shortest paths between any pair of vertices i and j (namely, the weight on the edge between them). For m > 1, an algorithm is developed that takes the minimum of paths of length m−1 and those that can be obtained by extending these paths one more step via an intermediate vertex k.
We will leave the details to the text, but it turns out that this algorithm for extending paths one step has structure almost identical to that for multiplying square matrices. The operations are different (min instead of addition, addition instead of multiplication), but the structure is the same. Both algorithms have three nested loops, so are O(V3) for extending one step.
After |V|−1 extensions, the paths will not get any shorter (assuming no negative weight edges), so one can iterate the path extending algorithm |V|−1 times, for an O(V4) algorithm overall: not very efficient.
However, the path extension algorithm, like matrix mutliplication, is associative, and we can use this fact along with the fact that results won't change after |V|−1 extensions to speed up the algorithm. We modify it to be like repeated squaring, essentially multiplying the resulting matrix by itself repeatedly. Then one needs only lg(V) "multiplications" (doubling of path length) to have paths longer than |V|, so the runtime overall is O(V3 lg V).
But we can do better with a different way of characterizing optimal substructure; one that does not just extend paths at their end, but rather allows two paths of length greater than 1 to be combined. That is what Floyd and Warshall figured out.
The textbook first develops a more complex version of this algorithm that makes multiple copies of matrices, and then notes in exercise 25.2-4 that we can reduce space requirements by re-using matrices. Here we go directly to that simpler version.
Assume that G is represented as an adjacency matrix of weights W = (wij), with vertices numbered from 1 to n. Diagonal elements are 0, representing the distance from each vertex to itself, and off-diagonal elements are the direct distance between those vertices that are connected, or ∞ if they are not:
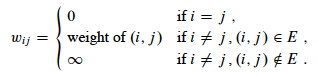
The all pairs shortest paths problem has optimal substructure because subpaths of shortest paths are shortest paths (previous lecture), and we have overlapping subproblems because a shortest path to one vertex may be extended to reach a further vertex.
We need to choose a recursive structure that exploits these properties. More than one recursive structure is possible, and Floyd and Warshall found a different recursive structure than that discussed in the previous section.
The subproblems are defined by computing, for 1 ≤ k ≤ |V|, the shortest path from each vertex to each other vertex that uses only vertices from {1, 2, ..., k}. That is:
Importantly, each step we can use what we just computed in the previous step, considering whether the kth vertex improves on paths found using vertices {1 ... k-1}. This is what enables us to leverage dynamic programming's ability to save and re-use solutions to subproblems.
The basic insight is that the shortest path from vertex i to vertex j using only vertices from {1, 2, ..., k} is either:
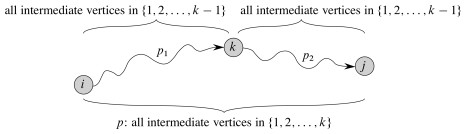
This way of characterizing optimal substructure allows the Floyd-Warshall algorithm to consider more ways of combining shortest subpaths than the matrix-multiplication-like algorithm did (which only extended paths by one at their ends).
This leads immediately to the classic Floyd-Warshall algorithm (as presented in excercise 25.2-4 and its public solution, as well as many other texts) for computing the shortest distances between all pairs:
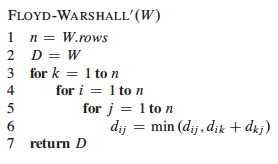
Please be sure that you understand how line 6 computes what is described as the "basic insight" and shown in the diagram above.
It's trivial; you tell me.
Although one can infer the shortest paths from the final weight matrix D, it is more straightforward to maintain a matrix of predecessor pointers just like we maintain predecessor pointers on individual vertices in the single-source version of shortest paths.
We update a matrix Π that is the same dimensions as D, and each entry πi,j contains the predecessor of vertex j on a shortest path from i (the predecessor on shortest paths from other vertices may differ).
The CLRS textbooks presentation shows us making a series of matrices Π(0) ... Π(n), but as with the weight matrix D we can actually do this in one matrix Π, and we can understand the superscripts (0) ... (n) as merely representing states of this matrix.
Examples of Floyd-Warshall, like of other dynamic programming problems, are tedious to work through. I invite you to trace though the example in the text, following the algorithm literally, and be prepared to do another example on homework. I won't talk through it here.
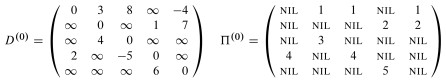
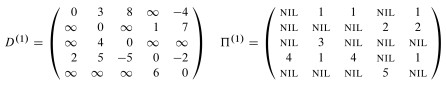
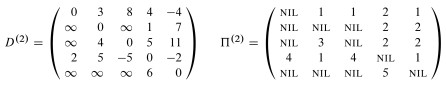
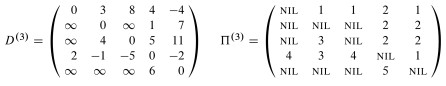
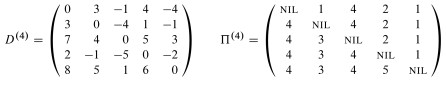
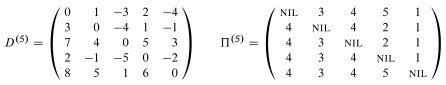
As this example shows, Floyd-Warshall works with negative weight edges. How would you use the final matrix to determine whether there are negative weight cycles?
Given that Johnson's is O(V E lg V), your analysis of Floyd-Warshall above, and that both handle negative weight cycles, which would you use on a sparse graph where E = O(V)? (Besides runtime, consider also that sparse graphs are best represented with adjacency lists.) Which would you use on a dense graph where E = O(V2)? (Besides runtime, consider also that matrix representations are not as wasteful of space for dense graphs.)
Suppose we have a graph G and we want to compute the transitive closure
G* = (V, E*) of G, where (u, v) ∈ E* iff ∃ path from u to v in G.
We can do this by assigning a weight of 1 to each edge, running the above algorithm, and then concluding there is a path for any (i, j) that have non-infinite path cost.
If all we care about is transitivity rather than path length, we can reduce space requirements and possibly speed up the algorithm by representing all edges as boolean values (1 for connected; 0 for not connected), and then modify Floyd-Warshall to use boolean OR rather than min and AND rather than addition. This reduces the space requirements from one numeric word to one bit per edge weight, and may be faster on machines for which boolean operations are faster than addition. See text for discussion.