We are presently covering this material in two days, with Chapter 8 and screencast 10C on the second day.
Quicksort, like Mergesort, takes a divide and conquer approach, but on a different basis.
If we have done two comparisons among three keys and find that x < p and p < y, do we ever need to compare x to y? Where do the three belong relative to each other in the sorted array?
By transitivity we already know that x < y without comparing them.
Quicksort uses this idea to partition the set of keys to be sorted into those less than the pivot p and those greater than the pivot. (It can be generalized to allow keys equal to the pivot.) It then recurses on the two partitions.
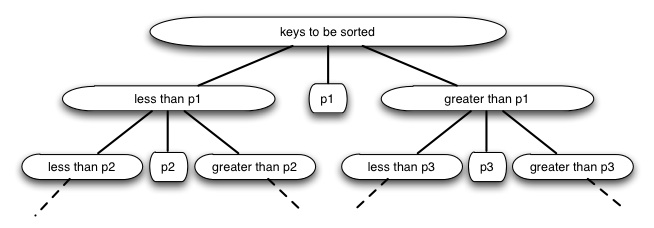
Compare this to Mergesort.
Quicksort performs well in practice, and is one of the most widely used sorts today.
To sort any subarray A[p .. r], p < r:
An array is sorted with a call to QUICKSORT(A, 1, A.length), or more generally we can sort any subrange of an array from p to r with QUICKSORT(A, p, r):

Clearly the above code handles primarily the "divide" aspect. The rest of the work is done in the PARTITION procedure. A[r] will be the pivot. (A[r] is the last element of the subarray A[p:r]. Given random data, the choice of the position of the pivot is arbitrary; working with element at the end simplifies the code):

At the end of the procedure, the item that was in A[r] will be in A[i+1] in the above code, or A[q] in the description at the beginning of this page.
PARTITION maintains four regions.
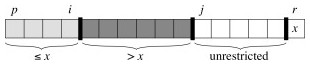
Three of these are described by the following loop invariants, and the fourth (A[j .. r-1]) consists of elements that not yet been examined:
Loop Invariant:
- All entries in A[p .. i] are ≤ pivot.
- All entries in A[i+1 .. j-1] are > pivot.
- A[r] = pivot.
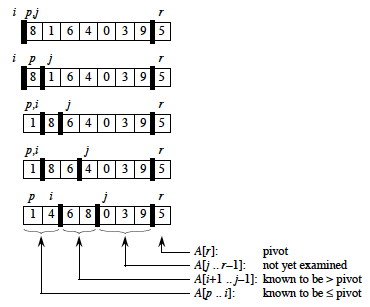
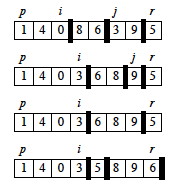
It is worth taking some time to trace through and explain each step of this example of the PARTITION procedure, paying particular attention to the movement of the dark lines representing partition boundaries.
Continuing ...
Here is the Hungarian Dance version of quicksort. Notice that they appear to be using a variation of the algorithm in which the pivot moves around as the items larger and smaller are shuffled around him!
We use the aforestated loop invariant to show correctness:
The formal analysis will be done on a randomized version of Quicksort. This informal analysis helps to motivate that randomization.
First, PARTITION is Θ(n): We can easily see that its only component that grows with n is the for loop that iterates proportional to the number of elements in the subarray).
The runtime depends on the partitioning of the subarrays:
The worst case occurs when the subarrays are completely unbalanced after partitioning, i.e., there are 0 elements in one subarray and n−1 elements in the other subarray (the single pivot is not processed in recursive calls). Then PARTITION must be called on n−1 elements. If this happens again, it will be called on n−2 elements, etc. This gives a familiar recurrence (compare to that for insertion sort):
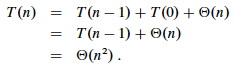
One example of data that leads to this behavior is when the data is already sorted: the pivot is always the maximum element, so we get partitions of size n−1 and 0 each time. Thus, quicksort is O(n2) on sorted data. Insertion sort actually does better on a sorted array! (O(n))
The best case occurs when the subarrays are completely balanced (the pivot is the median value): subarrays after pivoting have about n/2 elements. (One has n/2 and the other has (n/2)−1 due to removal of the pivot, but we'll ignore this difference for asymptotic analysis.) The recurrence is also familiar (compare to that for merge sort):
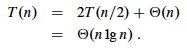
It turns out that expected behavior is closer to the best case than the worst case. Two examples suggest why expected case won't be that bad.
Suppose each call splits the data into 1/10 and 9/10. This is highly unbalanced: won't it result in horrible performance?
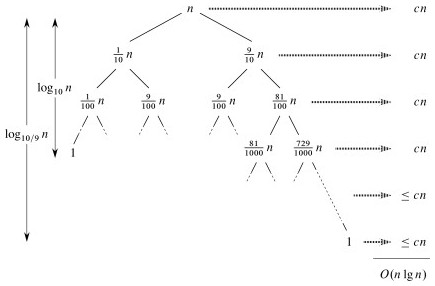
We have log10n full levels and log10/9n levels that are nonempty.
As long as it's constant, the base of the log does not affect asymptotic results. Any split of constant proportionality will yield a recursion tree of depth Θ(lg n). In particular (using ≈ to indicate truncation of low order digits),
log10/9n = (log2n) / (log210/9) by formula 3.15
≈ (log2n) / 0.152
= 1/0.152 (log2n)
≈ 6.5788 (log2n)
= Θ(lg n), where c = 6.5788.
So the recurrence and its solution is:
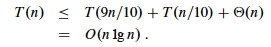
A general lesson that might be taken from this: sometimes, even very unbalanced divide and conquer can be useful.
With random data there will usually be a mix of good and bad splits throughout the recursion tree.
A mixture of worst case and best case splits is asymptotically the same as best case:

Both these trees have the same two leaves. The extra level on the left hand side only increases the height by a factor of 2, even if we iterate the same imbalance for subsequent levels, and this constant disappears in the Θ analysis.
Both result in O(n lg n), though with a larger constant for the left.

We expect good average case behavior if all input permutations are equally likely, but what if it is not?
To get better performance on sorted or nearly sorted data -- and to foil our adversary! (see Topic 5 notes, Randomized Algorithms section) -- we can randomize the algorithm to get the same effect as if the input data were random.
Instead of explicitly permuting the input data (which is expensive), randomization can be accomplished trivially by random sampling of one of the array elements as the pivot.
If we swap the selected item with the last element, the existing PARTITION procedure applies:



Now, even an already sorted array will give us average behavior.
Curses! Foiled again!
We now conduct a more formal analysis. The analysis assumes that all elements are unique, but with some work can be generalized to remove this assumption (Problem 7-2 in the text).
The previous analysis was pretty convincing, but was based on an assumption about the worst case. This analysis proves that our selection of the worst case was correct, and also shows something interesting: we can solve a recurrence relation with a "max" term in it!
PARTITION produces two subproblems, totaling size n−1. Suppose the partition takes place at index q. The recurrence for the worst case always selects the maximum cost among all possible ways of splitting the array (i.e., it always picks the worst possible q):
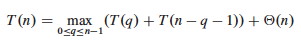
Based on the informal analysis, we guess T(n) ≤ cn2 for some c. Substitute this guess into the recurrence:
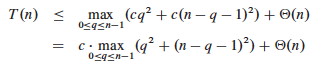
The maximum value of q2 + (n−q−1)2 occurs when q is either 0 or n-1 (the second derivative is positive, see exercise 7.4-3), and has value (n−1)2 in either case (easily verified by plugging in values for q):
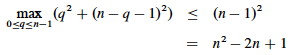
Substituting this back into the reucrrence:
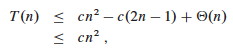
We can pick c so that c(2n−1) dominates Θ(n). Therefore, the worst case running time is O(n2).
One can also show that the recurrence is Ω(n2), so worst case is Θ(n2).
With a randomized algorithm, expected case analysis is much more informative than worst-case analysis. Why?
This analysis nicely demonstrates the use of indicator variables and two useful strategies.
Consider these facts: Each call to QUICKSORT or RANDOMIZED-QUICKSORT makes exactly one call to PARTITION or RANDOMIZED-PARTITION (which calls PARTITION). So the number of calls to either version of quicksort is the same as the number of calls to PARTITION.
Furthermore, the dominant cost of the algorithm is partitioning in PARTITION, as the work done in the other procedures is constant. PARTITION removes the pivot element from future consideration, so is called at most n times.
The amount of work in each call to PARTITION is a constant plus the work done in the for loop of lines 3-6. We can count the number of executions of the for loop by counting the number of comparisons performed in line 4.
It would be difficult to count the number of comparisons in each call to PARTITION, as it depends on the data.It is easier to derive a bound on the number of comparisons across the entire execution or across ALL calls to PARTITION.
This is an example of a strategy that is often useful: if it is hard to count one way (e.g., "locally"), then count another way (e.g., "globally").
Let X be the total number of comparisons in all calls to PARTITION. The total work done over the entire execution is O(n + X), since QUICKSORT does constant work setting up n calls to PARTITION, and the work in PARTITION is proportional to X. But what is X?
For ease of analysis,
We want to count the number of comparisons. Each pair of elements is compared at most once, because elements are compared only to the pivot element and then the pivot element is never present in any later call to PARTITION.
Indicator variables can be used to count the comparisons. (Recall that we are counting across all calls, not just during one partition.)
Let Xij = I{ zi is compared to zj }
Since each pair is compared at most once, the total number of comparisons is:
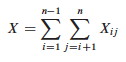
Taking the expectation of both sides, using linearity of expectation, and applying Lemma 5.1 (which relates expected values to probabilities):

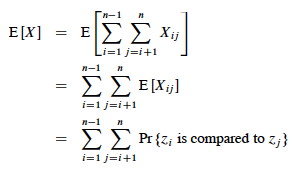
What's the probability of comparing zi to zj?
Here we apply another useful strategy: if it's hard to determine when something happens, think about when it does not happen.
Elements (keys) in separate partitions will not be compared. If we have done two comparisons among three elements and find that zi < x <zj, we do not need to compare zi to zj (no further information is gained), and QUICKSORT makes sure we do not by putting zi and zj in different partitions.
On the other hand, if either zi or zj is chosen as the pivot before any other element in Zij, then that element (as the pivot) will be compared to all of the elements of Zij except itself.
Therefore (using the fact that these are mutually exclusive events):
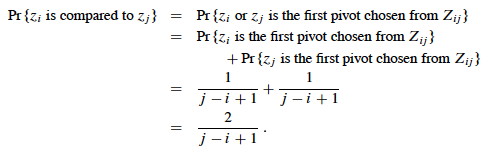
We can now substitute this probability into the analyis of E[X] above and continue it:
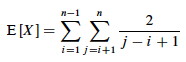
This is solved by applying equation A.7 for harmonic series, which we can match by substituting k = j−i and shifting the summation indices down i:
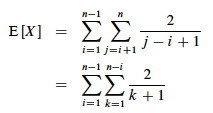
We can get rid of that pesky "+ 1" in the denominator by dropping it and switching to inequality (after all, this is an upper bound analysis), and now A7 (shown in box) applies:
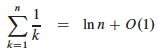
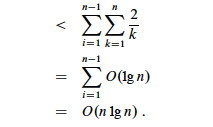
Above we used the fact that logs of different bases (here, ln n and lg n) grow the same asymptotically.
To recap, we started by noting that the total cost is O(n + X) where X is the number of comparisons, and we have just shown that X = O(n lg n).
Therefore, the average running time of QUICKSORT on uniformly distributed permutations (random data) and the expected running time of randomized QUICKSORT are both O(n + n lg n) = O(n lg n).
This is the same growth rate as merge sort and heap sort. Empirical studies show quicksort to be a very efficient sort in practice (better than the other n lg n sorts) whenever data is not already ordered. (When it is nearly ordered, such as only one item being out of order, insertion sort is a good choice.)
We have been studying sorts in which the only operation that is used to gain information is pairwise comparisons between elements. So far, we have not found a sort faster than O(n lg n).
It turns out that it is not possible to give a better guarantee than O(n lg n) in a comparison sort.
The proof is an example of a different level of analysis: of all possible algorithms of a given type for a problem, rather than particular algorithms ... pretty powerful.
A decision tree abstracts the structure of a comparison sort. A given tree represents the comparisons made by a specific sorting algorithm on inputs of a given size. Everything else is abstracted, and we count only comparisons.
For example, here is a decision tree for insertion sort on 3 elements.
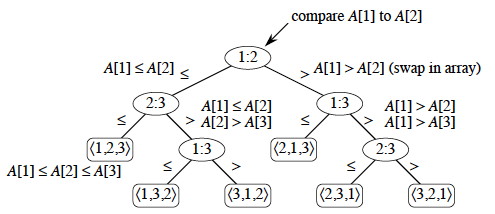
Each internal node represents a branch in the algorithm based on the information it determines by comparing between elements indexed by their original positions. For example, at the nodes labeled "2:3" we are comparing the item that was originally at position 2 with the item originally at position 3, although they may now be in different positions.
Leaves represent permutations that result. For example, "⟨2,3,1⟩" is the permutation where the first element in the input was the largest and the third element was the second largest.
This is just an example of one tree for one sort algorithm on 3 elements. Any given comparison sort has one tree for each n. The tree models all possible execution traces for that algorithm on that input size: a path from the root to a leaf is one computation. The longest path from the root to a leaf is the longest possible computation for that n.
We don't have to know the specific structure of the trees to do the following proof. We don't even have to specify the algorithm(s): the proof works for any algorithm that sorts by comparing pairs of keys. We don't need to know what these comparisons are. Here is why:
We get our result by showing that the number of leaves l for a tree of input size n implies that the tree must have minimum height Ω (n lg n). This will be a lower bound on the running time of any comparison sort algorithm.
h ≥ lg(n/e)n
= n lg(n/e)
= n lg n − n lg e
= Ω (n lg n).
since lg e is a constant. Thus, the height of a decision tree that permutes n elements to all possible permutations cannot be less than n lg n.
A path from the leaf to the root in the decision tree corresponds to a sequence of comparisons. Therefore there will always be some input that requires at least Ω(n lg n) comparisons in any comparison based sort.
There may be some specific paths from the root to a leaf that are shorter. For example, when insertion sort is given sorted data it follows an O(n) path. In fact, this is Θ(n) because to verify that a sorted data set is sorted, a comparison algorithm must make n − 1 = Ω(n) comparisions (the first key to the second, the second to the third, ... the n−1th key to the nth.
But to give an o(n lg n) guarantee (i.e, strictly better than O(n lg n)), one must show that all paths are shorter than O(n lg n), or that the tree height is o(n lg n) and we have just shown that this is impossible since the height of the tree is Ω(n lg n): this is the best a comparison sort can do
Under some conditions it is possible to sort data without comparing two elements to each other. If we know something about the structure of the data we can sometimes achieve O(n) sorting. Typically these algorithms work by using information about the keys themselves to put them "in their place" without comparisons. We introduce these algorithms briefly so you are aware that they exist.
Assumes (requires) that keys to be sorted are integers in {0, 1, ... k}.
For each element in the input, counting sort determines how many elements are less than or equal to that input.
Then we can place each element directly in a position that leaves room for the elements below it.

As you can see, Counting-Sort places the results in a new array B: it is not an in-place sort. It also requires an array C that counts the number of elements of a given key and also controls the placement of elements in B.
An example: (a) is after lines 4-5 complete; (b) is after lines 7-8 complete; (c) through (d) show the placement of the first three elements in lines 10-12; and (f) shows the final sorted array.
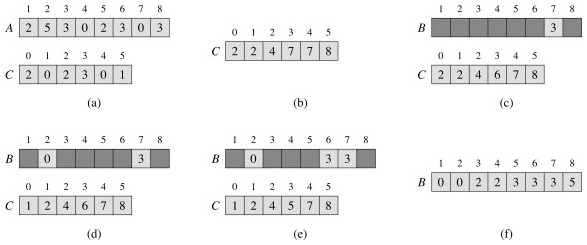
Counting-Sort is a stable sort, meaning that two elements that are equal under their key will stay in the same order as they were in the original sequence. This is a useful property that we return to in the next section.
Counting-Sort requires Θ(n + k) time. Since k is constant in practice, this is Θ(n).

Using a stable sort like counting sort, we can sort from least to most significant digit:
This is how punched card sorters used to work. (When I was an undergraduate student my university still had punched cards, and we had to do an assignment using them mainly so that we would appreciate not having to use them!)
The code is trivial, but requires a stable sort and only works on n d-digit numbers in which each digit can take up to k possible values:
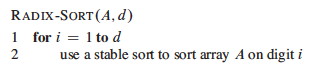
Note that digit 1 is the least significant (right most) digit, and i counts up from right to left (not left to right as in array indexing).
If we use the Θ(n + k) counting sort as the stable sort, then RADIX-SORT is Θ(d(n + k)) time.
This one is reminiscent of hashing with chaining.
It maps the keys to the interval [0, 1), placing each of the n input elements into one of n-1 buckets. If there are collisions, chaining (linked lists) are used. Thus it requires extra storage proportional to n (it is not in-place).
Then it sorts the chains before concatenating them.
It assumes that the input is from a random distribution, so that the chains are expected to be short (bounded by constant length).

The numbers in the input array A are thrown into the buckets in B according to their magnitude. For example, 0.78 is put into bucket 7, which is for keys 0.7 ≤ k < 0.8. Later on, 0.72 maps to the same bucket: like chaining in hash tables, we "push" it onto the beginning of the linked list.
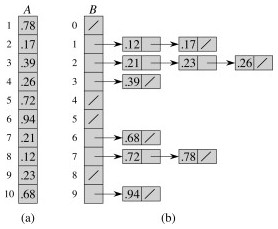
At the end, we sort the lists (figure (b) shows the lists after they are sorted; otherwise we would have 0.23, 0.21, 0.26) and then copy the values from the lists back into an array. CLRS provide a long analysis with indicator random variables to show that the total expected time of sorting all the linked lists with insertion sort is linear in n.
But sorting linked lists is awkward, and I am not sure why CLRS's pseudocode and figure imply that one does this. In an alternate implementation, steps 7-9 can be done simultaneously: scan each linked list in order, inserting the values back into array A and keeping track of the next free position. Insert the next value at this position and then scan back to find where it belongs, swapping if needed as in insertion sort. Since the values are already partially sorted, an insertion procedure won't have to scan back very far. For example, suppose 0.78 came in the 7th list before 0.72. The insertion would only have to scan over one item to put 0.78 in its place, as all values in lists 0..6 are smaller.

You can also compare some of the sorts with these animations (set to 50 elements): http://www.sorting-algorithms.com/. Visualizations are not a silver bullet: you'll need to study them carefully. They are probably good for comparing two algorithms.
The above site points out that no sort has all desired properties, but when you don't need a stable sort a good version of quicksort is the best general purpose choice.
Quoting directly from https://www.toptal.com/developers/sorting-algorithms:
The ideal sorting algorithm would have the following properties:There is no algorithm that has all of these properties, and so the choice of sorting algorithm depends on the application.
- Stable: Equal keys aren’t reordered.
- Operates in place, requiring O(1) extra space.
- Worst-case O(n·lg(n)) key comparisons.
- Worst-case O(n) swaps.
- Adaptive: Speeds up to O(n) when data is nearly sorted or when there are few unique keys.
We return to the study of trees, with balanced trees.