Two sets A and B are disjoint if they have no element in common.
Sometimes we need to group n distinct elements into a collection Š (we'll call that "S-hat", though it's a "caron") of disjoint sets Š = {S1, ..., Sk} that may change over time.
Disjoint set data structures are also known as Union-Find data structures, after the two operations in addition to creation: Applications often involve a mixture of searching for set membership (Find) and merging sets (Union).
Make-Set(x): make a new set Si = {x} (x will be its representative) and add Si to Š.
Union(x, y): if x ∈ Sx and y ∈ Sy, then Š ← Š − Sx − Sy ∪ {Sx ∪ Sy} (that is, combine the two sets Sx and Sy).
- The representative of Sx ∪ Sy is any member of that new set (implementations often use the representative of one of Sx or Sy.)
- Union destroys Sx and Sy, since the sets must be disjoint (they cannot co-exist with Sx ∪ Sy).
Find-Set(x): return the representative of the set containing x.
- We don't return the set itself because the representative is how we reference the set.
We analyze in terms of:
Students commonly get confused by n and m: be clear that for this topic n is the number of items in the data structure and m is the number of operations on the data structure.
Some facts we can rely on:
Union-Find on disjoint sets is used to find structure in other data structures, such as a graph. We initially assume that all the elements are distinct by putting them in singleton sets, and then we merge sets as we discover the structure by which the elements are related.
In the next topic we cover algorithms to find minimum spanning trees of graphs. Kruskal's algorithm will use Union-Find operations.
Recall from Topic 14 that for a graph G = (V, E), vertices u and v are in the same connected component if and only if there is a path between them.
Here is an algorithm for computing connected components in an undirected graph:

Would that work with a directed graph? Why or why not?
Once the above has run, we can use this algorithm for testing whether two vertices are in the same component:

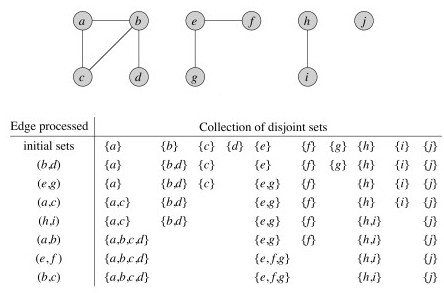

Although it is easy to see the connected components above, the utility of the algorithm becomes more obvious when we deal with large graphs (such as the one pictured)!
In a static undirected graph, it is faster to run Depth-First Search (exercise 22.3-12), or for static directed graphs the strongly connected components algorithm of Topic 14 (section 22.5), which consists of two DFS. But in some applications edges may be added to the graph. In this case, union-find with disjoint sets is faster than re-running the DFS after each edge is added.
One might think that lists are the simplest approach, but there is a better approach that is not any more complex: this section is mainly for comparision purposes.
Each set is represented using an unordered singly linked list. The list object has attributes:
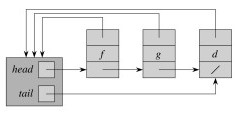
Each object in the list has attributes for:
First try:
For example, let's take the union of S1 and S2, replacing S1:
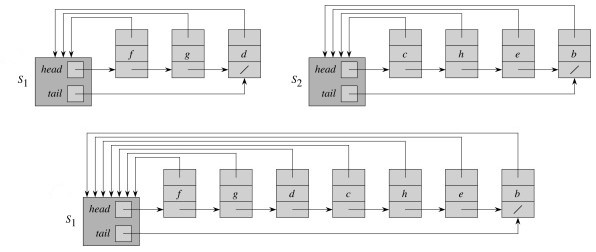
This can be slow for large data sets. For example, suppose we start with n singletons and always happend to append the larger list onto the smaller one in a sequence of merges:
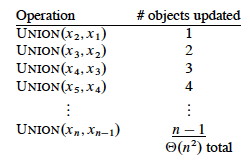
If there are n Make-Sets and n Unions, the amortized time per operation is O(n)!
A weighted-union heuristic speeds things up: always append the smaller list to the larger list (so we update fewer set object pointers). Althought a single union can still take Ω(n) time (e.g., when both sets have n/2 members), a sequence of m operations on n elements takes O(m + n lg n) time.
Sketch of proof: Each Make-Set and Find-Set still takes O(1). Consider how many times each object's set representative pointer must be updated during a sequence of n Union operations. It must be in the smaller set each time, and after each Union the size of this smaller set is at least double the size. So:
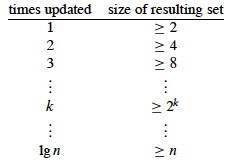
Each representative set for a given element is updated ≤ lg n times, and there are n elements plus m operations. However, we can do better!
The following is a classic representation of Union-Find, due to Tarjan (1975). The set of sets is represented by a forest of trees. The code is simple, but the analysis of runtime is complex!
The ADT operations correspond to tree operations as follows:
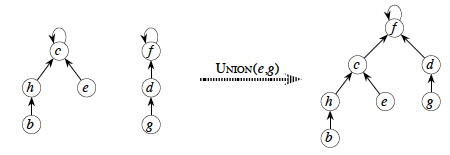
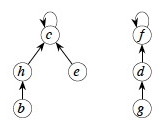
Here's an example: Union(e,g) will find the set e is in
by following parent pointers to c, and the set g is in by
following parent pointers to f, and then make one of these trees a child
of the other:
Note that this example does NOT include the rank and path compression heuristics to be discussed below. (After you read about path compression, see whether you can identify which path should be compressed.)
In order to avoid degeneration to linear trees, and achieve amazing amortized performance, these two heuristics are applied:
Union by Rank: make the root of the "smaller" tree a child of the root of the "larger" tree. But rather than size we use rank, an upper bound on the height of each node (stored in the node).
See Link below for implementation of these heuristics.
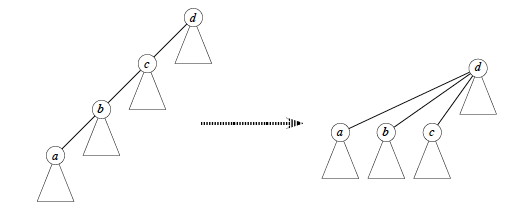
Path Compression: When running Find-Set(x), make all nodes on the path from x to the root direct children of the root. For example, suppose we call Find-Set(a) on the lefthand tree (the triangles represent arbitrary subtrees):
See Find below for implementation of this heuristic.
The algorithms are very simple! (But their analysis is complex!) We assume that nodes x and y are tree nodes with the client's element data already initialized.

Link implements the union by rank heuristic.
Find-Set implements the path compression heuristic. It makes a recursive pass up the tree to find the path to the root, and as recursion unwinds it updates each node on the path to point directly to the root. (This means it is not tail recursive, but as the analysis shows, the paths are extremely unlikely to be long.)
The analysis can be found in section 21.4. It is very involved, and I only expect you to know what is discussed below. It is based on a very fast growing function:
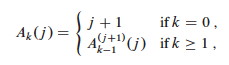
Ak(j) is a variation of Ackerman's Function, which is what you will find in most classic texts on the subject. The function grows so fast that A4(1) = 16512 is much larger than the number of atoms in the observable universe (1080)!
The result uses α(n), a single parameter inverse of Ak(j) defined as the lowest k for which Ak(1) is at least n:
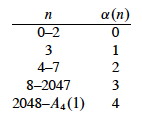
α(n) = min{k : Ak(1) ≥ n}
α(n) grows very slowly, as shown in the table. We are highly unlikely to ever encounter α(n) > 4 (we would need input size much greater than the number of atoms in the universe). Although its growth is strictly larger than a constant, for all practical purposes we can treat α(n) as a constant.
The analysis of section 21.4 shows that the running time is O(m α(n)) for a sequence of m Make-Set, Find-Set and Union operations, or O(α(n)) per operation. Since α(n) > 4 is highly unlikely, for all practical purposes the cost of a sequence of m such operations is O(m), or O(1) amortized cost per operation!!
Note: If asked on a quiz or exam what the amortized time complexity of a union-find operation in the forest with heuristics implementation, write O(α(n)), not O(1). Then you may add that it is for all practical purposes O(1).
We now return to Graphs, where we will see Union-Find used to compute minimum spanning trees.